This paper introduces the Canonical Graph Pattern (CGP), a design approach for building web-based, agentic interfaces. Instead of offering new research or technical solutions, the goal is to help product designers, engineers, and AI practitioners see how structured data, app routes, and large language models can work together. By looking at the basics of CGP, we want to share a new way to build systems that are easier to explain, more context-aware, and better suited for agents.
Challenges of Building Agentic Interfaces
Large language models generate smooth, relevant text. The problem: they’re often not connected to real data or key relationships in the app. Their answers may sound good, but can be inconsistent, unverifiable, or unrelated to actual app events.
Challenge 1: Lack of Scoped Context
Many traditional systems just feed the LLM a bunch of unstructured text, such as entire documents or web pages, and hope it can make sense of it.
The LLM gets too much information at once. It’s hard to manage, unfocused, and rarely matches what the user actually needs right now.
This setup makes chatting with the LLM feel disconnected. The LLM isn’t integrated; it’s separate from the app’s core.
Instead of giving focused context, the LLM gets the entire application at once. That defeats smart, targeted reasoning. After all, the goal is to provide the user with the right information when they need it.
Challenge 2: Lack of Verifiability
Even when the LLM pulls up the right information, there’s no way for it to verify that it actually matches the official data in the system.
It might read a product description, but it can’t verify whether the product actually exists or whether its details match the real source of truth.
That uncertainty makes people trust the system less. The interface isn’t truly agentic, because being agentic means the system is aware of what it’s doing and responsible for it.
Towards a Solution: The CGP
Given these challenges, how can we build better agentic interfaces? Enter the Canonical Graph Pattern (CGP).
CGP provides a way to build agentic interfaces you can trust, with the right context always available.
At its heart, CGP is about a few key things: 1) Turning structured data into graph entities with clear, shared meaning (where a graph entity is a node representing a distinct item in your system), 2) Connecting those entities to application routes (routes are the paths or URLs that correspond to specific pages or states in your application), and 3) Giving LLMs and agents just the right, route-based context they need, no more and no less.
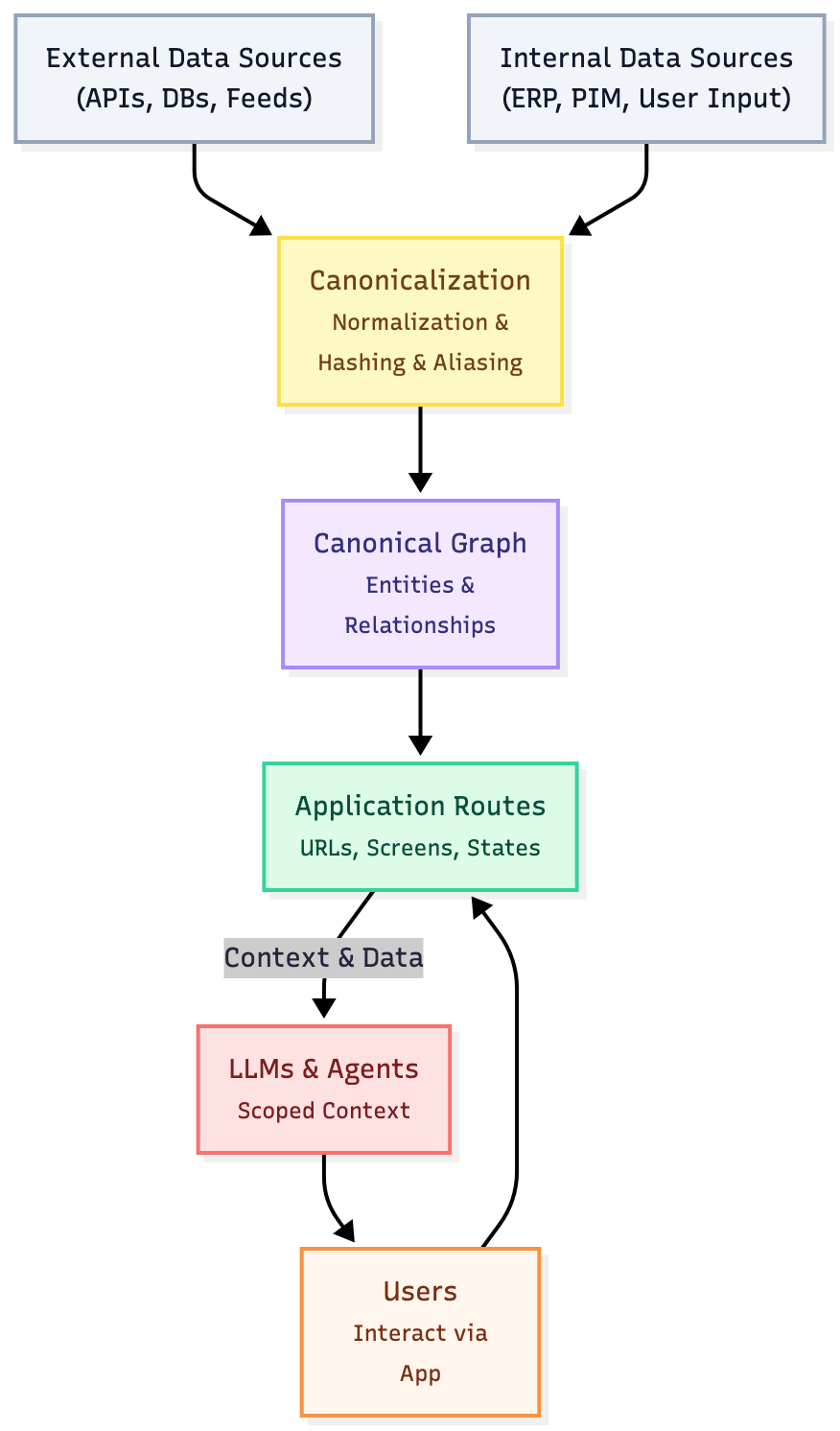
This approach links your data’s identity to your app’s structure, enabling LLMs to use trustworthy, up-to-date information.
With this pattern, every application route matches a specific entity in your graph.
With this pattern, the LLM always knows its context and focuses only on relevant areas, rather than the entire system.
“Don’t let your app be a collection of pages—turn it into a living map of real things.”
Note that the Canonical Graph Pattern works for all types of apps, not just web. In mobile apps, for example, screens—rather than routes—map to canonical entities. More generally, “state” means any app condition linked to a canonical entity. This paper focuses on web apps, so we use routes as context for LLMs.
Canonical IDs
A canonical identifier is a special key that links your apps and data graphs to the same thing.
“One canonical ID means one version of the truth—no more duplicates, no more confusion.”
It’s a stable, reliable ID that always points to the real thing, no matter where it shows up or what it’s called.
For example, if two things are really the same, even if they come from different files or have different names, they still get the same canonical ID.
A canonical ID ensures that every system part refers to the same thing consistently and is machine-checkable.
The Canonical Graph
A knowledge graph is a network of things—like products or people—and their links, like dots and lines on a map.
A canonical graph takes this one step further by giving every item a canonical ID —its true, stable identity —and one or more aliases —the names people actually use.
The graph identifies duplicate entries and merges them into a single trusted version.
For LLMs, canonical IDs are anchors of truth. With them, the LLM always refers to real things. In older knowledge graphs, names varied, which could lead to confusion in references.
Canonical graphs turn a messy web of names into a clear, trustworthy map of real things.
“A canonical graph connects the dots—so every entity and relationship has one true identity.”
Building the Graph: Practical Example
Let’s walk through a real-world example for e-commerce. Imagine you run a store that pulls product data from many sources, such as Shopify, your ERP, a product info system, and some marketing feeds. They all talk about the same product—a pair of shoes—but the details are different every time. Each system has its own version.
One system calls the product “Nike Pegasus 40 running shoes”, while another calls it “Pegasus 40 running shoes”.
Both are talking about the same real product, but they use different formats and names.
Canonicalization ensures all versions—and every agent—refer to the same thing.
“Canonicalization isn’t about what things are called. It’s about what they truly are, and how they fit together.”
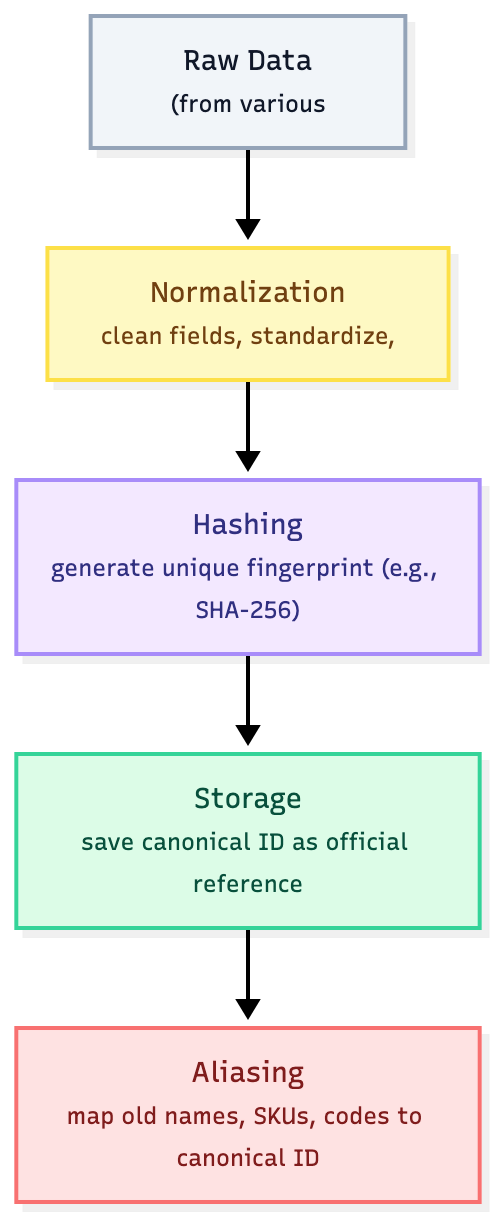
Here’s how it works.
1. Normalization
First, clean up the data by stripping extraneous fields, unifying field names, and preserving the original order so identical records match.
{
"brand": "Nike",
"category": "Sportswear",
"name": "Nike Pegasus 40 running shoes"
}2. Hashing
Hash the cleaned data (e.g., SHA-256) to generate a unique “fingerprint.”
const hash = sha256(JSON.stringify(normalizedProduct));This gives you a canonical ID, like:
canonical_id = "product#b4e92da1"
3. Storage
Now, save that fingerprint as the official ID. Everywhere in your system, that ID means you’re talking about the same item.
| canonical_id | type | source | data |
|---|---|---|---|
| product#b4e92da1 | Product | Shopify | {...} |
| product#b4e92da1 | Product | ERP | {...} |
4. Aliasing
Finally, link all the different names, product codes, or old system IDs back to this main ID. It doesn’t matter what people call it; if the details are the same, it always maps to this single, trusted identity.
| alias | canonical_id |
|---|---|
| shopify_456 | product#b4e92da1 |
| NIKE-PPR-002 | product#b4e92da1 |
| /products/nike-pegasus-40 | product#b4e92da1 |
Canonicalization Process
Canonical Graphs and Agents
For agentic interfaces, a canonical graph gives agents and LLMs information they can trust instantly.
Graphs alone aren’t enough—agents and users must be able to access data when needed. Without this, graphs are unused visualizations.
But there’s more. LLMs don’t just need the graph; they need context. The graph is just a collection of things and their links. What matters is what’s important to the user right now. Usually, you want to start with a “neighborhood” of related things, not the whole map.
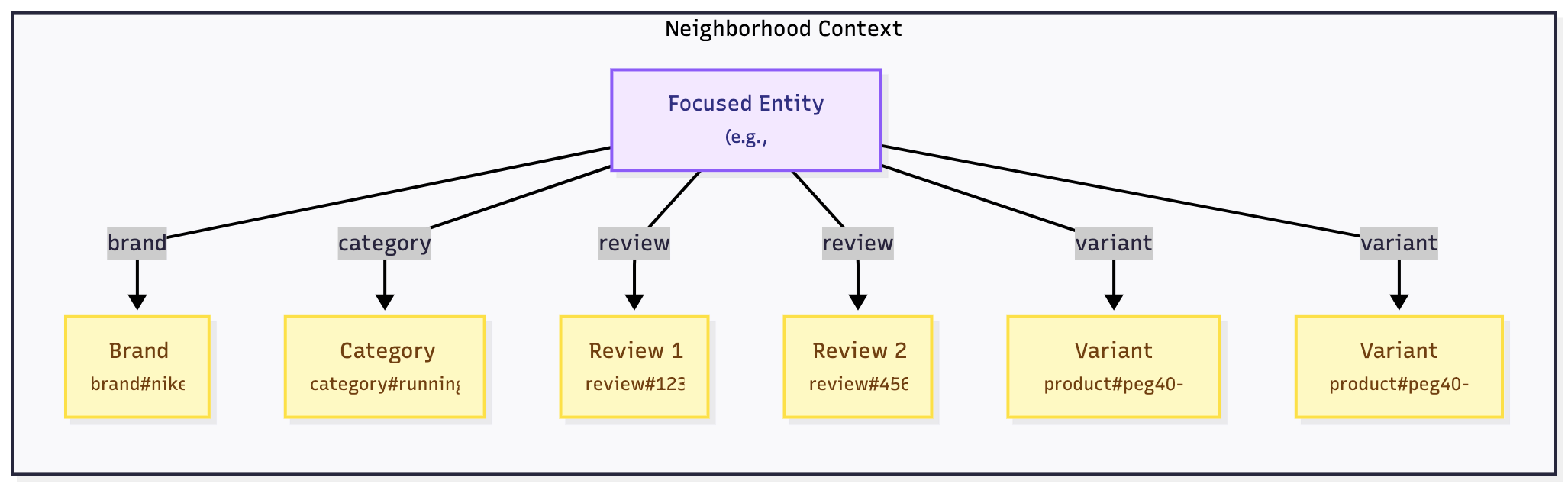
Context keeps things fast. Give the LLM only the information needed for the task, not the whole graph.
Canonical graphs make data trustworthy, but context is key. The Canonical Graph Pattern links resources with routes for relevant context.
“AI gets smarter when it knows where it is, not just what it sees.”
Routes as Doorways to Context and Verifiability
Let’s talk about routes for a minute. Routing is how your app turns a URL, such as /products/shoes or /products/shoes/nike-pegasus-40, into a specific page.
Usually, routes just show a page. The system doesn’t really know the content; it’s just HTML, without verification.
LLMs can summarize page info, but they’re not verifying facts. There’s no guarantee that ‘Nike Pegasus 40 running shoes’ and ‘Pegasus 40 running shoes’ are the same. The link between route, text, and the real thing is weak.
Routing in the Canonical Graph Pattern
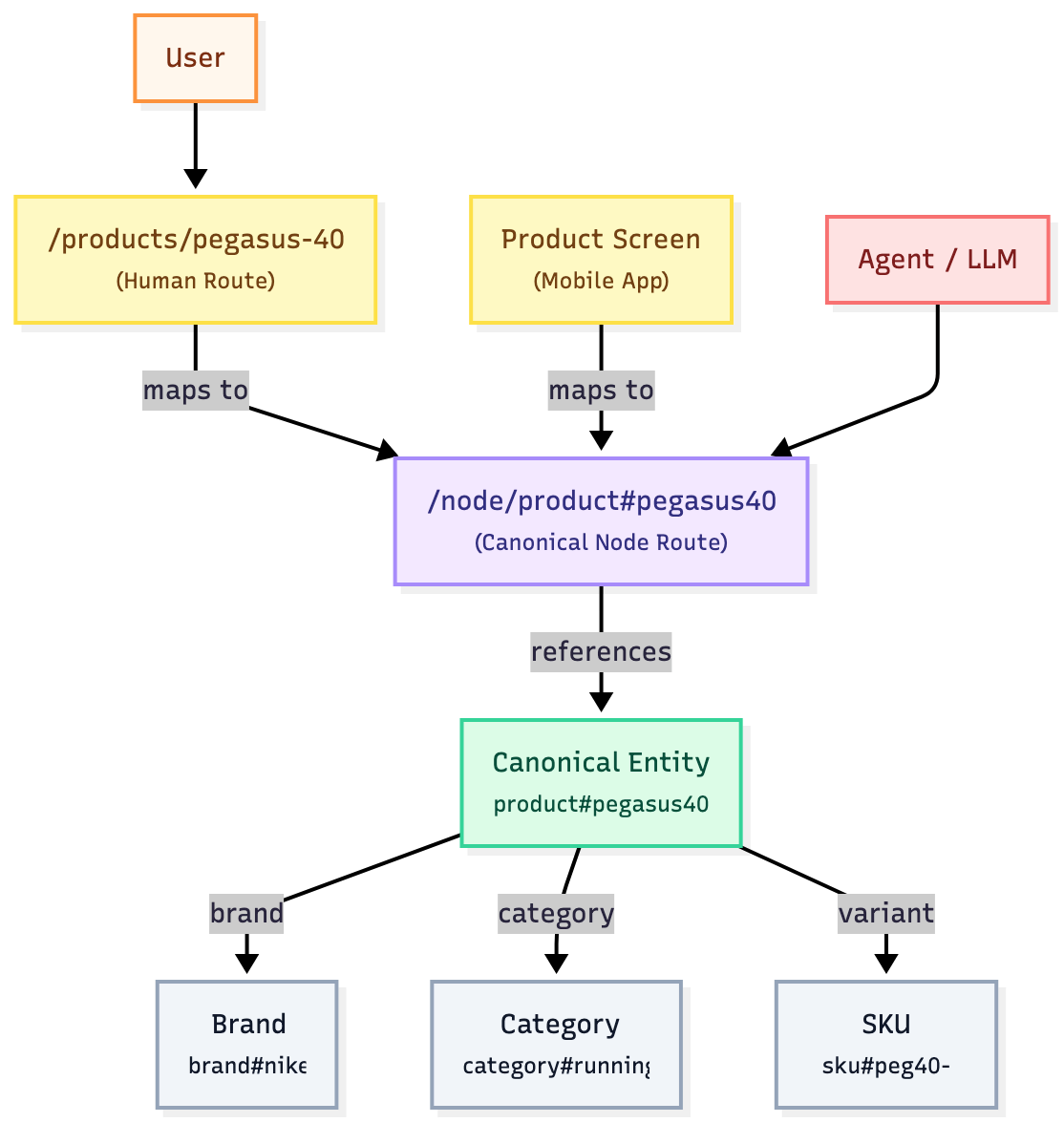
Now, in the Canonical Graph Pattern, routing does a lot more. Every route in your app maps to a canonical resource—an authoritative item in your graph.
So, instead of each page just being a chunk of text, every route is now a doorway into your graph. It points directly to a specific entity that LLMs and agents can understand and reason about.
The way your app is built aligns with how you organize your knowledge.
Every page connects to a real node in the graph.
This brings some huge benefits:
- Context-awareness. The route tells your system exactly what the user is looking at.
- Verifiability: The route connects to a canonical ID, so you know you’re always talking about the same thing, no matter where you are.
- Explainability: Agents can say exactly what resource they used to answer a question.
- Interoperability: Both people and machines can navigate the system in the same way.
Routing: Practical Example
Let’s see how this works in practice. Take this route:
/products/north-face-arctic-expedition-tent
When someone visits this page, the app knows it matches the canonical entity:
/node/product#f2a7b9e1
Here’s how it breaks down:
- The human route (
/products/north-face-arctic-expedition-tent) is clear and easy for people to read. - The machine route (
/node/product#f2a7b9e1) points right to the canonical product for agents and LLMs.
When you’re on this page, the system provides the LLM with all the relevant context, such as the canonical resource, its attributes (e.g., description, price, and brand), and its relationships to other products in a category like “Tents”.
With this context, an agent can answer questions like:
“What temperature can this tent handle?”
or
“Show similar tents rated for below -40°C.”
It can also explain where it found the info:
“I referenced
product#f2a7b9e1and related entities incategory#b8d4c6e9.”
The LLM (acting as an agent) can also query related products.
Why Routes Matter in CGP
Routes aren’t just web addresses—they’re coordinates that tell both people and systems exactly what an entity is and where it fits in your knowledge graph.
“Routes aren’t just web addresses—they’re doorways into your app’s knowledge.”
In the Canonical Graph Pattern, routes become trusted entry points to the right data. A user’s location in the app instantly defines the scope for smart answers, and agents can always back up their responses with a specific, canonical source.
Think of it this way: The graph holds the truth, routes open the door, and the LLM is the guest who always knows exactly where they are.
Search, re-defined in CGP
In CGP, search and chat are the same thing. Type something in a search bar, and instead of a static list of results, a chat window opens with your query already there. Or start a chat — and the AI automatically searches, guided by where you are in the app and what you’ve been doing. The model isn’t guessing — it’s reasoning from context.
How this builds on existing search
Most systems mix three kinds of search:
- Keyword search — classic text matching. Works for exact terms, not meaning.
- Vector search — finds items similar in meaning by comparing text embeddings (numerical representations of words and phrases).
- Graph-based search — uses structured data (entities and relationships) to find connected or linked things.
These all work in isolation, but they share the same problem: They’re stateless, detached from user context, and non-verifiable.
They don’t remember what you just did. They don’t know where you are in the app or what you’ve already seen. And they can’t prove that what they retrieved is the right thing — only that it’s probably relevant.
What CGP changes
CGP introduces contextual state into search.
Every part of an app — a route, a page, a screen — maps to a canonical entity in a graph. That entity has relationships to others (its neighborhood), forming a structured context. When you search, that context is already in play. The AI starts reasoning from where you are — not from scratch.
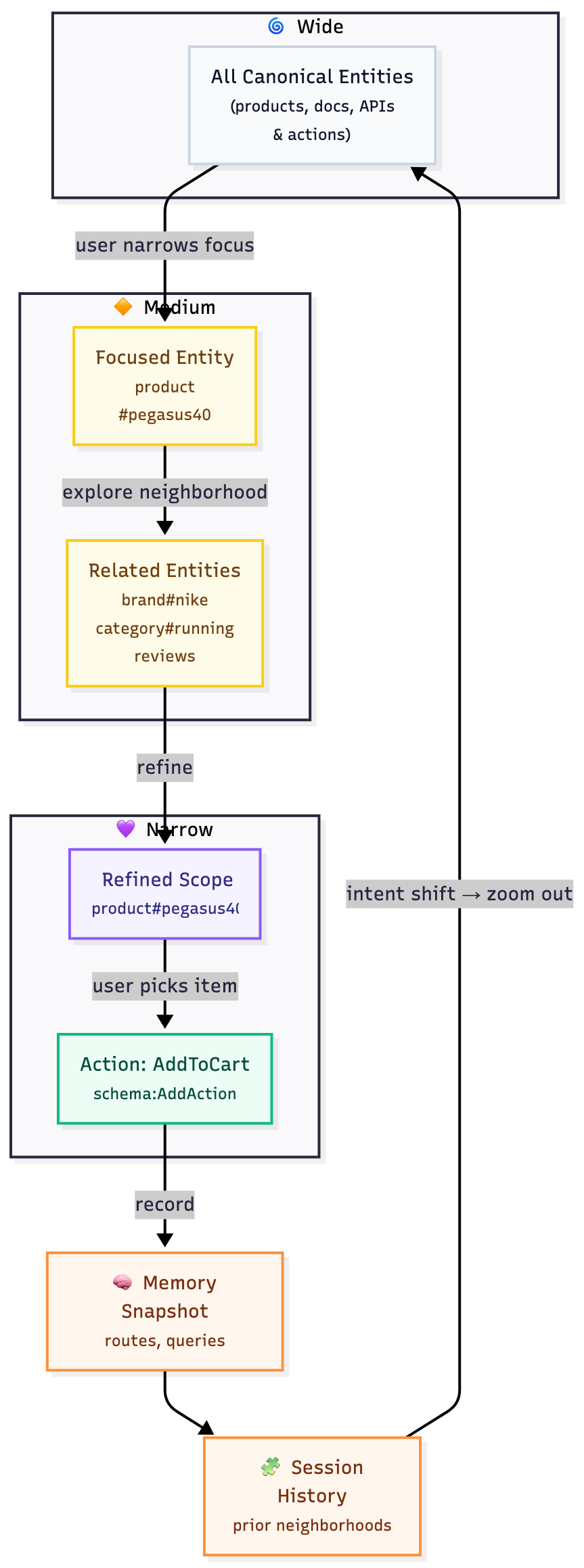
But context in CGP isn’t static. It’s dynamic, evolving as the user moves through the app. At the start of a session, context is broad—the entire domain graph. As you navigate, search, and interact, the system narrows its focus to the neighborhood of entities you’ve touched.
Later, it can widen if your intent changes or if you complete an action, such as adding a product to your cart. The LLM’s “field of attention” becomes a living, shifting subgraph — not a fixed prompt.
Think of it like a camera lens that zooms in or out on the graph depending on what you’re doing.
Each interaction, search, or click is also logged as a schema:Action, feeding into the app’s memory. This builds a record of how users explore and connect concepts.
Context naturally adapts as users move around, so the model always focuses on what matters most in the moment. Instead of searching everywhere at once, it reasons locally, making everything faster and more relevant. And, just like people, the system remembers where you’ve been and what you’ve done.
CGP vs. retrieval layers
In traditional systems, vector or graph search sits behind the app — a backend retrieval service. In CGP, the app itself is the graph interface. Each route (or state) is a portal into a canonical entity. Search, memory, and reasoning happen within that context, not outside it.
Other search: “Fetch everything possibly relevant.” CGP: “You’re here. Let’s reason about this node and the ones around it — and remember what you’ve done along the way.”
In Conclusion
The Canonical Graph Pattern (CGP) is all about making apps smarter and more reliable for both users and AI. Instead of treating your app like a bunch of disconnected pages, CGP connects everything—your data, IDs, and routes—into a living map of real things.
With CGP, language models and agents don’t have to guess what’s relevant. They get the right context every time and can always check their work against authoritative data.
This makes apps easier to use, easier to explain, and more trustworthy. Context adapts as users move around, and every step is grounded in what’s actually true—not just free-floating text.
It’s a simple shift in how apps are built, but it could change how we interact with smart systems for good.